GreenFinger is a high-performance, highly scalable distributed web crawler built in Java. Designed for both enterprise and individual users, it offers an intuitive user interface and minimal configuration, enabling seamless and efficient web resource extraction. As an open-source solution, GreenFinger provides a powerful yet user-friendly approach to large-scale web crawling and data acquisition.
🌟Features:
-
Seamless Spring Boot Integration Natively integrates with Spring Boot, ensuring effortless configuration, deployment, and maintenance.
-
Scalable, High-Throughput Distributed Crawling Architected for distributed environments, enabling seamless horizontal scaling to handle massive workloads efficiently.
-
Optimized Network Communication with Netty Leverages Netty for ultra-low-latency networking, with additional support for Mina and Grizzly for flexible communication strategies.
-
Enterprise-Grade URL Deduplication Implements billion-scale deduplication using Bloom Filter and RocksDB, ensuring optimal storage efficiency and crawl accuracy.
-
Granular URL Customization Supports fine-grained control over URL selection, allowing users to define initial URLs, retain only relevant URLs, and exclude undesired links dynamically.
-
Advanced Fault Tolerance & Crawler Constraints Incorporates intelligent retry mechanisms, configurable timeouts, target URL limits, and maximum crawl depth enforcement for robust error handling.
-
Multi-Engine Web Content Extraction Integrates Playwright, Selenium, and HtmlUnit to capture and process dynamic web content efficiently.
-
Strict Adherence to Robots.txt Fully complies with the Robots Exclusion Protocol, ensuring ethical and responsible web crawling.
-
Comprehensive Developer API Exposes a rich set of APIs, enabling seamless customization, extension, and integration into diverse ecosystems.
-
Automated Authentication Handling Supports intelligent login and logout workflows, facilitating seamless authentication across secured web portals.
-
Version-Controlled Web Document Management Assigns unique versioning to crawled documents, enabling multi-version indexing for enhanced content tracking and retrieval.
-
Intuitive Angular-Based Web Interface Provides a modern, interactive dashboard built with Angular, empowering users with real-time monitoring, configuration, and management capabilities.
🚀 Technology Stack
| Technology | Version Requirement | Description |
|---|---|---|
| ☕ JDK | 17 or later | Core Java runtime environment |
| 🌱 Spring Boot | 2.7.18 | Backend framework for microservices and rapid development |
| ⚡ Netty | 4.x | High-performance asynchronous networking framework |
| 🔥 Redis | 7.x or later | In-memory data store for caching and message queuing |
| 🐘 PostgreSQL | 9.x or later | High-performance, open-source relational database |
| 🔍 ElasticSearch | 7.16.2 or later | Distributed search and analytics engine |
| 🕷 Selenium | 4.x | Web automation framework for headless and UI-based scraping |
| 🎭 Playwright | 1.48 | Modern browser automation tool for scraping and testing |
| 📄 HtmlUnit | 2.6 | Lightweight headless browser for quick HTML processing |
| 🌐 Angular | 19.x | Frontend framework for building interactive web applications |
| 🎨 Angular Material | Latest | UI component library for modern, responsive designs |
Install:
- Git Repository https://github.com/paganini2008/greenfinger.git
- Directory Structure
📂 greenfinger
├── 📂 greenfinger-ui
│ ├── 📜 pom.xml
│ ├── 📂 src
│ │ ├── 📂 config # Configuration files
│ │ ├── 📂 db # Database-related scripts and configurations
│ │ └── ...
├── 📂 greenfinger-spring-boot-starter
│ ├── 📜 pom.xml
│ ├── 📂 src
│ └── ...
├── 📜 LICENSE
├── 📜 pom.xml
└── 📜 README.md
Steps:
- Modify configuration:
spring:
redis:
database: 0
host: 127.0.0.1
port: 6379
password: 123456
elasticsearch:
rest:
uris: http://127.0.0.1:9200
connection-timeout: 10000
read-timeout: 60000
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/test?characterEncoding=utf8&allowMultiQueries=true&useSSL=false&stringtype=unspecified
username: admin
password: 123456
# Binding host name is preferred
doodler:
transmitter:
nio:
server:
bindHostName: 127.0.0.1
# Internal Work ThreadPool Threads
greenfinger:
workThreads: 1000
- Create database and import table scripts execute db/crawler.sql
mvn clean install-
run jar with
java --add-opens=java.base/java.lang=ALL-UNNAMED -jar greenfinger-ui-service-1.0.0-SNAPSHOT-sources.jar - Open the Web UI http://localhost:6120/ui/index.html

Greenfinger UI Guide
Catalog Management
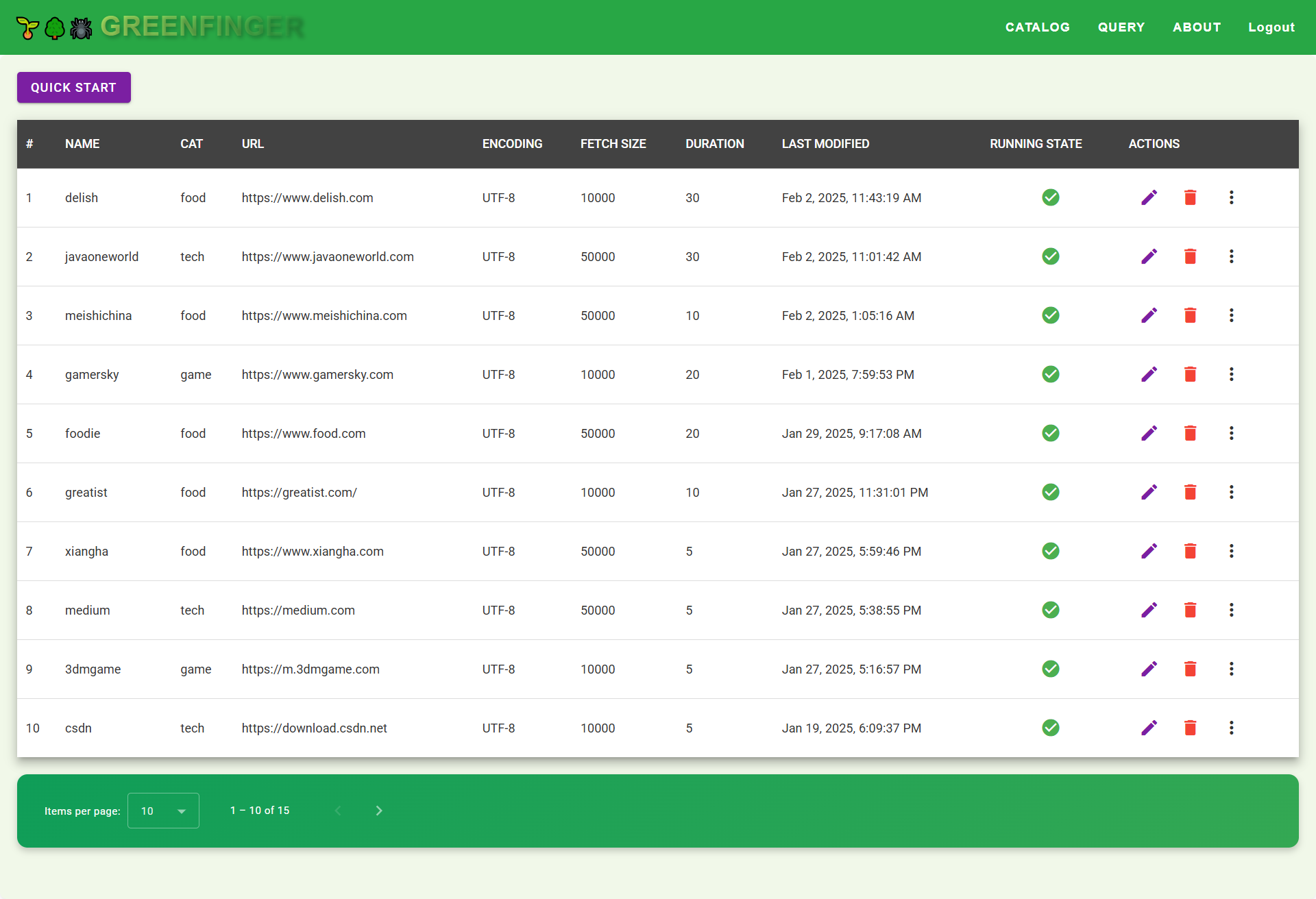
Create a catalog
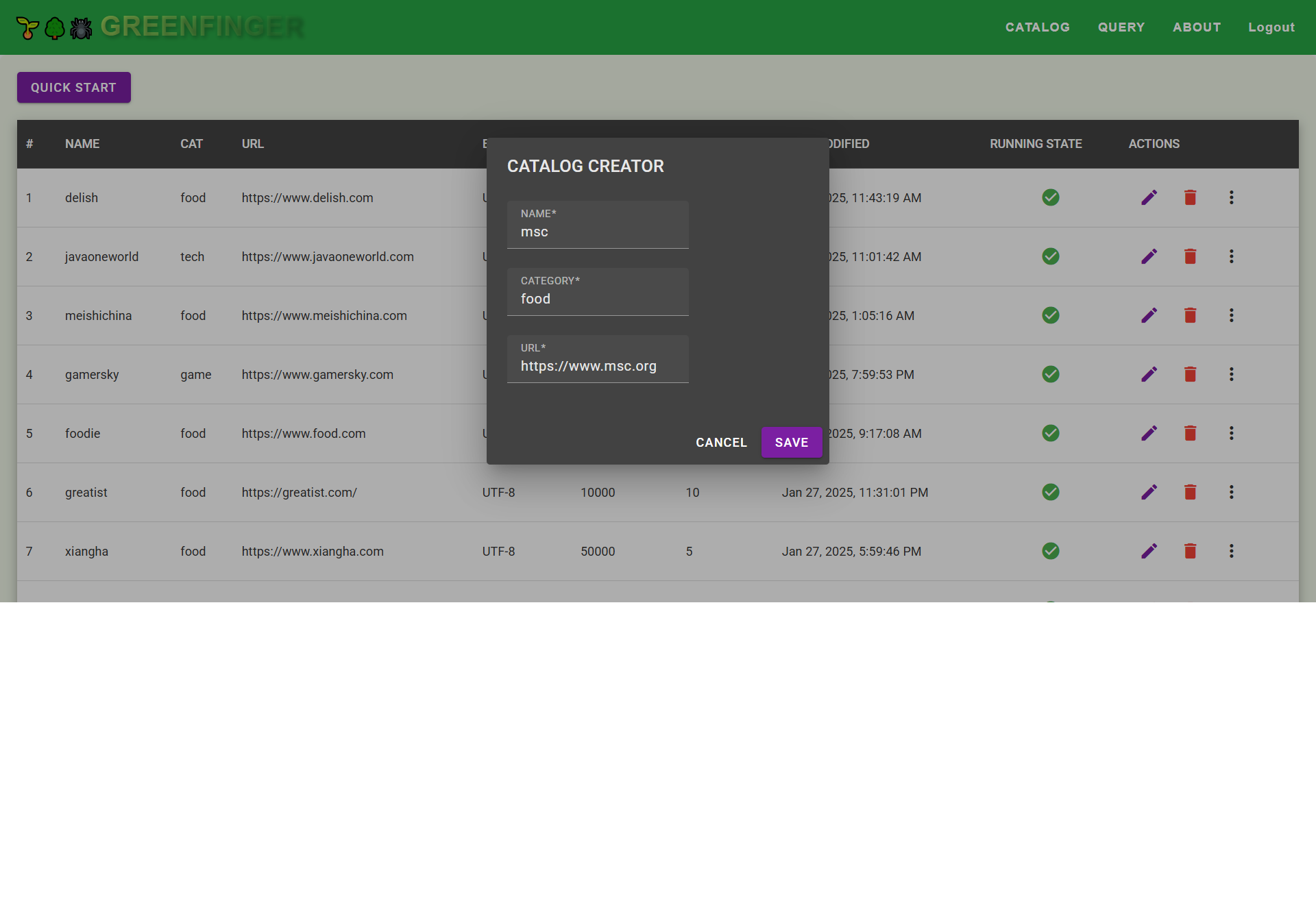
Edit a catalog
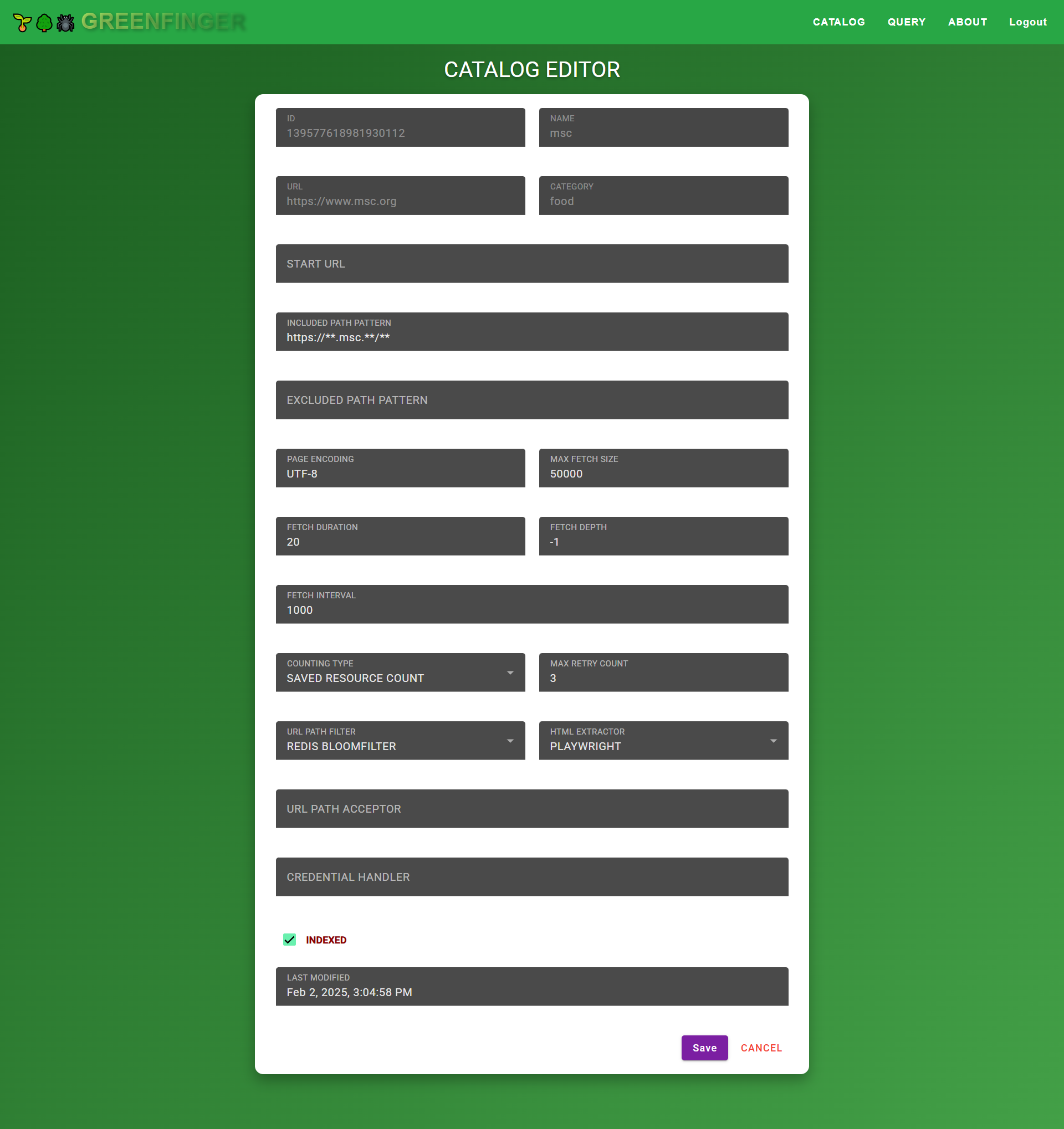
📌 Parameters
| Parameter | Description |
|---|---|
| ID | Unique identifier for the catalog entry. |
| Name | The name of the catalog item. |
| URL | The target website to be crawled. |
| Category | User-defined category for classification. |
| Start URL | The initial entry point for crawling. |
| Included Path Pattern | Defines URL patterns to be included in the crawl. |
| Excluded Path Pattern | Defines URL patterns to be excluded from crawling. |
| Page Encoding | Character encoding of the webpage (e.g., UTF-8). |
| Max Fetch Size | The maximum number of URLs to fetch in a single crawl session. |
| Fetch Duration | The total duration (in seconds) the crawl process should run. |
| Fetch Depth | Defines how deep the crawler should go (-1 means unlimited depth). |
| Fetch Interval | Time interval (in milliseconds) between consecutive requests. |
| Counting Type | Determines how crawled data is counted: |
| - Total Fetched Count (all requests made) | |
| - Filtered Count (URLs removed by filters) | |
| - Failed Count (requests that failed) | |
| - Saved Resource Count (stored data) | |
| - Indexed Count (successfully indexed pages) | |
| - Duplicate Count (repeated entries detected) | |
| Max Retry Count | The number of times a failed request will be retried. |
| URL Path Filter | Duplicate URL filtering mechanism: |
| - Redis BloomFilter (efficient large-scale deduplication) | |
| - RocksDB (persistent local storage-based deduplication) | |
| HTML Extractor | Webpage extraction engine: |
| - Playwright (modern headless browser automation) | |
| - Selenium (full-browser-based interaction) | |
| - HtmlUnit (lightweight Java-based HTML parsing) | |
| URL Path Acceptor | Defines custom URL patterns to be accepted during crawling. |
| Credential Handler | Custom Login Handler (full class name) for handling authentication logic. |
| Indexed Checkbox | Determines whether the crawled data should be indexed (Checked = Yes). |
| Last Modified | Timestamp of the last modification. |
| Save Button | Confirms and saves the catalog settings. |
| Cancel Button | Discards changes and exits the editor. |
Run web crawler
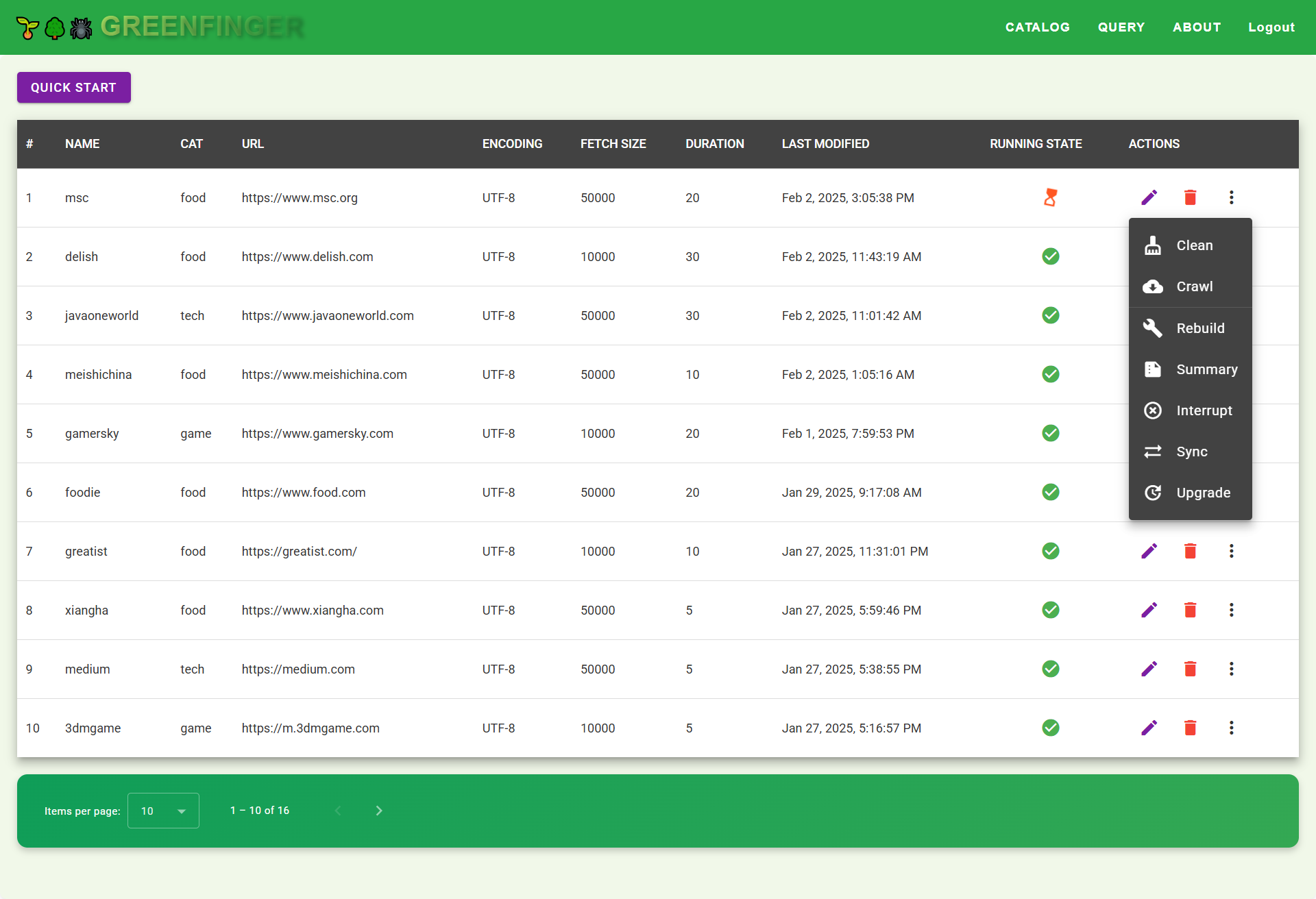
| Icon | Action | Description |
|---|---|---|
| 🧹 Clean | Remove unnecessary or outdated data to free up space. | |
| 🌐 Crawl | Start a new crawling session to gather updated data. | |
| 🛠 Rebuild | Restart the crawler to reprocess and fetch data again. | |
| 📄 Summary | View a high-level summary of the crawling results and statistics. | |
| ❌ Interrupt | Stop an ongoing crawling session immediately. | |
| 🔄 Sync | Synchronize data with external sources or distributed nodes. | |
| 🚀 Upgrade | Perform system upgrades, applying new features or patches. |
Monitor
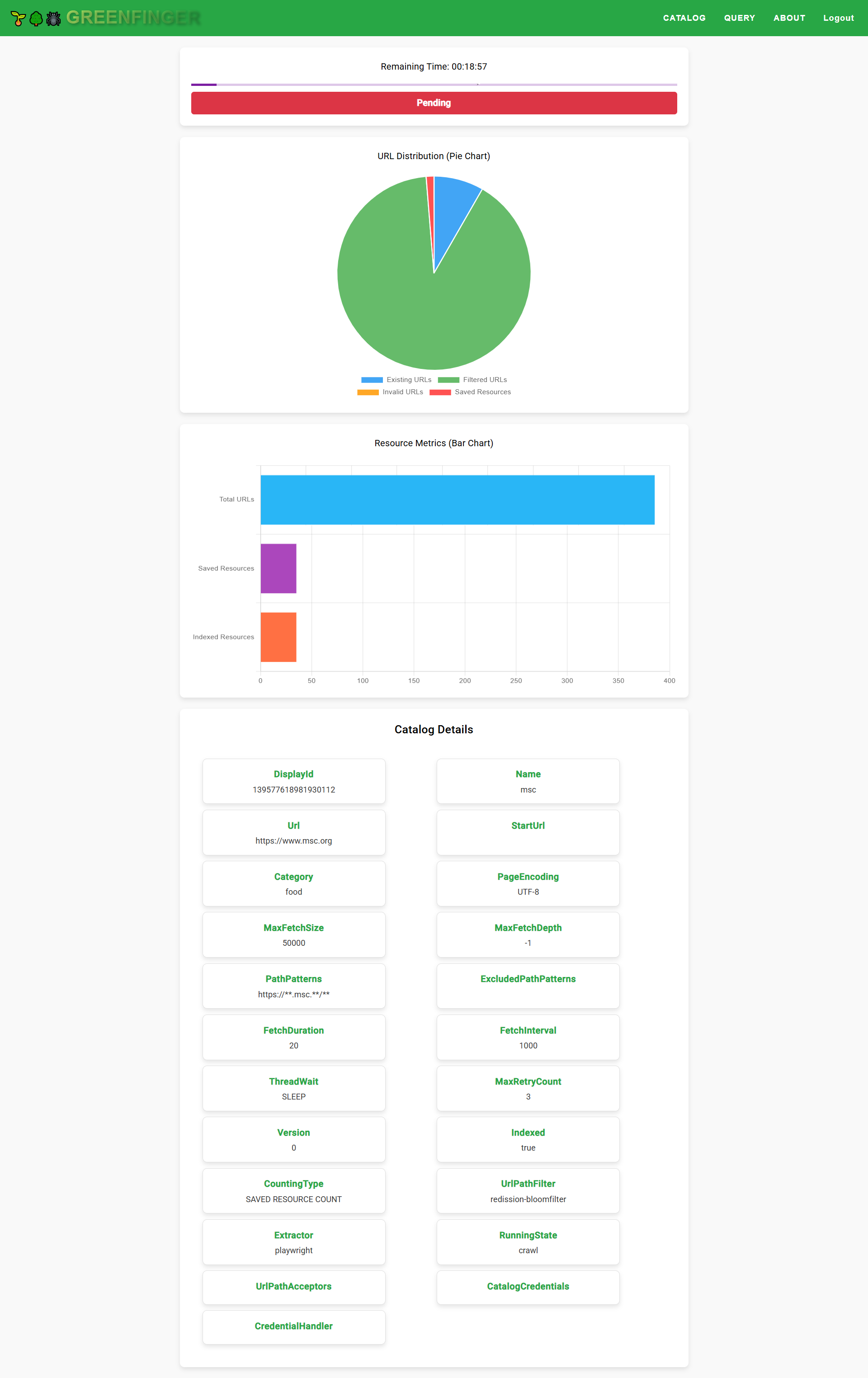
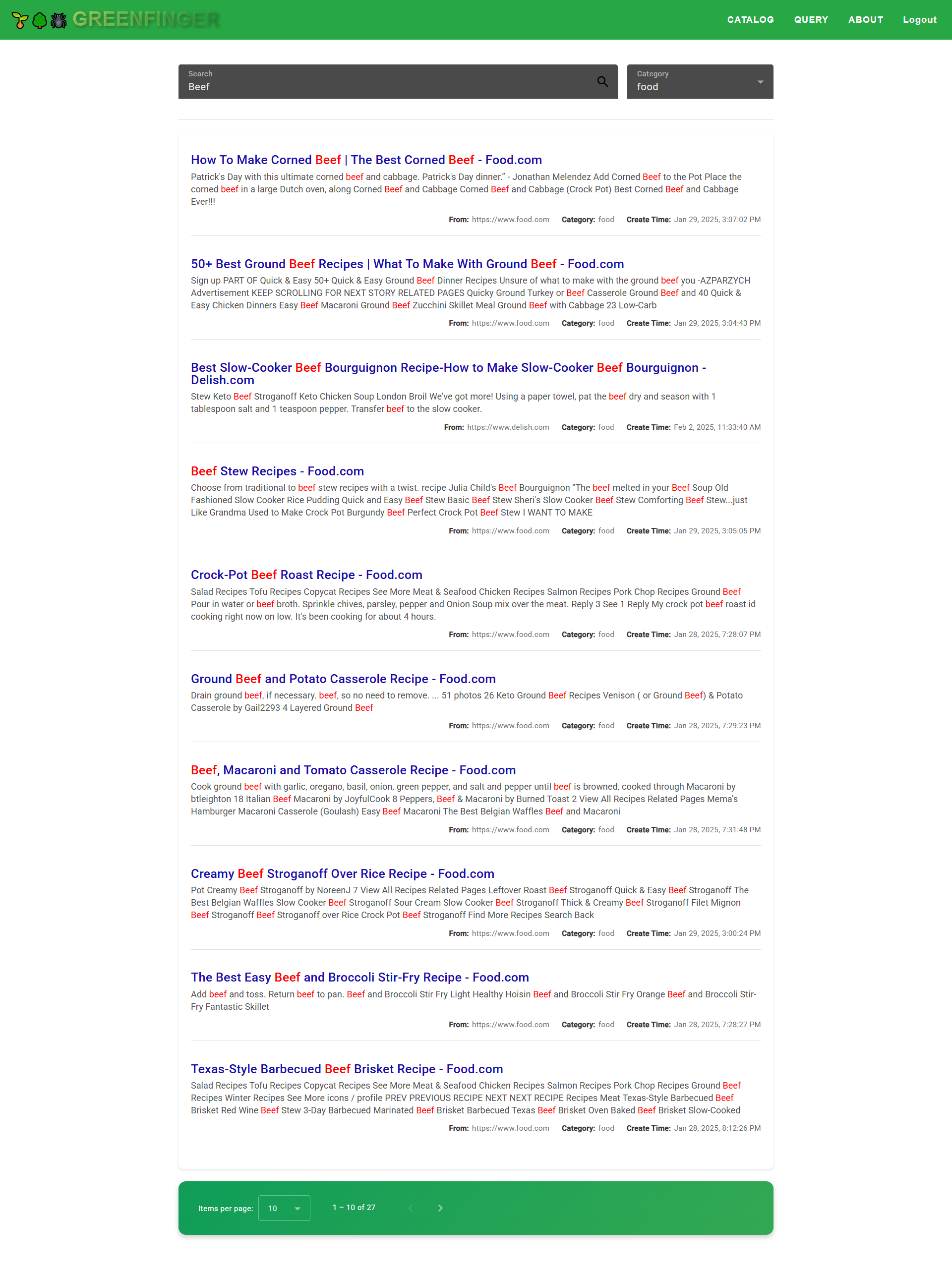
Query
Customize your application
Application Integration
Step1: add dependency in your pom.xml:
<dependency>
<groupId>com.github.paganini2008</groupId>
<artifactId>greenfinger-spring-boot-starter</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
Step2: add @EnableGreenFingerServer on the main:
@EnableAsync(proxyTargetClass = true)
@EnableScheduling
@EnableGreenfingerServer
@SpringBootApplication
public class GreenFingerServerConsoleMain {
public static void main(String[] args) {
SpringApplication.run(GreenFingerServerConsoleMain.class, args);
}
}
Step3: Run it
Extensible points:
| Interface | Description |
|---|---|
| ResourceIndexManager | Manages indexing operations for crawled resources, ensuring efficient storage, retrieval, and versioning of indexed data. |
| ResourceManager | Handles the lifecycle of crawled URLs, including storage, deduplication, and scheduling for further processing. |
| ExistingUrlPathFilter | Implements a URL deduplication mechanism to prevent redundant crawling of previously processed URLs. |
| GlobalStateManager | Maintains and synchronizes the global state of the crawler across distributed nodes, ensuring coordinated execution. |
| InterruptionChecker | Monitors execution status and provides mechanisms to gracefully interrupt crawling operations when necessary. |
| UrlPathAcceptor | Defines a custom business logic filter for URL acceptance, allowing precise control over which URLs are processed. |
| ExtractorCredentialHandler | Provides a pluggable authentication handler to automate login flows for accessing restricted content. |
| Extractor | Defines the component responsible for extracting page content, supporting multiple implementations such as Playwright, Selenium, and HtmlUnit. |
🚀 Future Roadmap
| 🎯 Feature | 📌 Description | 🏗 Status |
|---|---|---|
| 🔄 Full Spring Boot 3 Support | Upgrade core framework to fully support Spring Boot 3, ensuring compatibility with the latest Java ecosystem. | 🚧 In Progress |
| 📈 Enhanced Web Scraping Quality | Improve parsing accuracy, anti-bot detection, and JavaScript rendering for better data extraction. | 🎯 Planned |
| 📡 Distributed Crawler Cluster Monitoring | Implement real-time monitoring, failure recovery, and dynamic scaling for large-scale web crawlers. | 🔍 Researching |
| 🗄 Support for Multiple Databases | Extend support beyond PostgreSQL, adding MySQL, MongoDB, and Redis for flexible storage options. | 🎯 Planned |